cc_glob_draw.py
import glob
def read_all(file_list):
data = []
for f in file_list:
ifile = open(f, 'r', encoding='utf-8')
data += ifile.read()
ifile.close()
return data
#print(all_data)
#add codes for counting all words
from collections import Counter
def counts(data, top=10):
wc_list = Counter(data).most_common(top)
w_list, c_list = zip(*wc_list)
return w_list, c_list
f_list = glob.glob('news_data/*.txt')
all_data=read_all(f_list)
wlist, clist = counts(all_data)
#print(wlist)
#print(clist)
# bar 로 jpg 파일 그리기
from draw_bar import draw_bar
from Han_fonts import set_Han_font
set_Han_font()
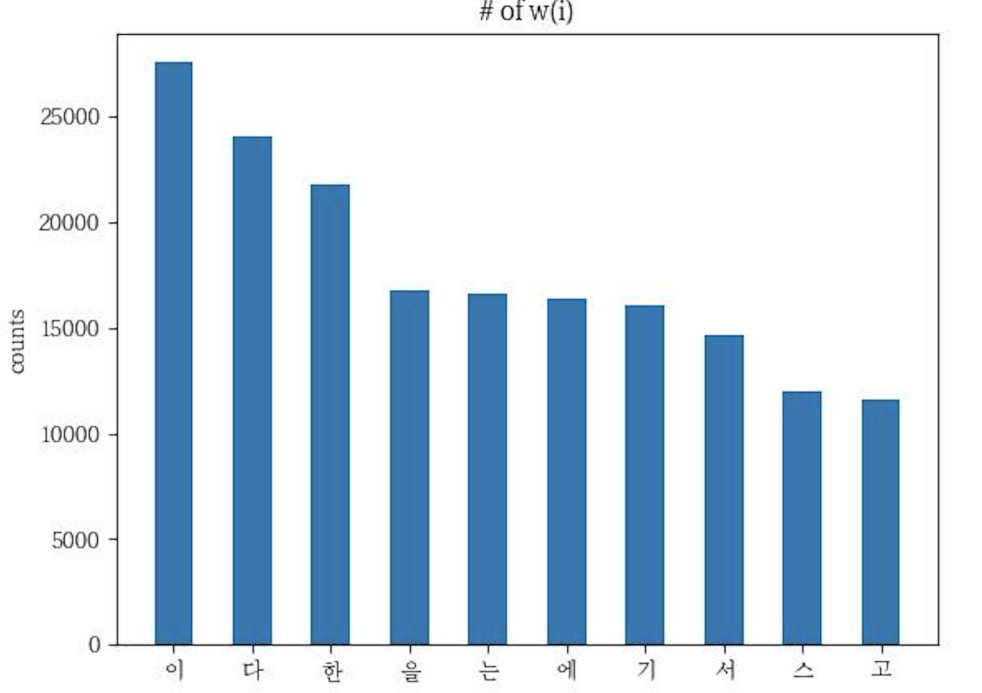
draw_bar(wlist, clist, filename)read_all() : 각 파일들의 데이터 data 에 다 저장하기
counts() : 상위 10개의 가장 많이 나온 글자의 리스트를 w_list 로 반환해주고 c_list 는 개수를 반환해준다.
그리고 draw_bar 를 import 해서 그려준다.
draw_bar.py
import matplotlib.pyplot as plt
def draw_bar(w_list,c_list, figname='bar_of_counts.jpg'):
plt.bar(w_list,c_list,width=0.5)
plt.ylabel('counts')
plt.title('# of w(i)')
plt.savefig(figname)
plt.show()
if __name__ == "__main__":
xaxis =['w1','w2','w3','w4','w5']
yaxis=[1,3,5,7,9]
draw_bar(xaxis,yaxis)
이제 여러 변형이 가능하다.
글자가 한글인 경우에만 count 하도록 만들어주기
cl_han_glob_draw.py
import glob
from collections import Counter
from draw_bar import draw_bar
from Han_fonts import set_Han_font
from Hangul import *
def read_all(file_list):
data = []
for f in file_list:
ifile = open(f, 'r', encoding='utf-8')
data += ifile.read()
ifile.close()
return data
#print(all_data)
#add codes for counting all words
def counts(data, top=10):
wc_list = Counter(data).most_common(top)
w_list, c_list = zip(*wc_list)
return w_list, c_list
def is_hangul_chr(char):
#'가' ~ '힣'
if 0xac00 <= ord(char) <= 0xd7ac : return True
return False
f_list = glob.glob('news_data/*.txt')
all_data=read_all(f_list)
all_han_data = [sylla for sylla in all_data if is_hangul_chr(sylla) ]
h = Hangul()
all_han_letters = [letter for sylla in all_han_data for letter in h.decompose(sylla)]
#all_han_letters = [letter for sylla in all_han_data for letter in h.decompose(sylla) if letter != '']
wlist, clist = counts(all_han_letters)
#print(wlist)
#print(clist)
set_Han_font()
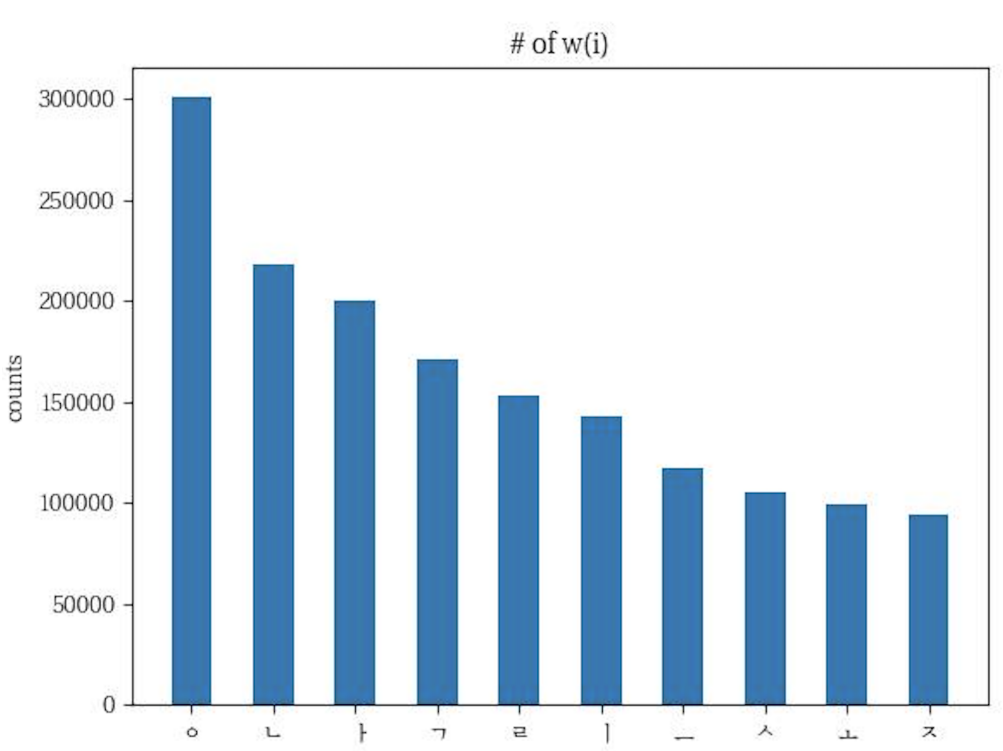
draw_bar(wlist, clist, 'han_syllables.jpg')all_data[] 는 모든 데이터 한 글자씩 저장된 리스트이다.
all_han_letters 은 두가지가 있다.
위는 한글인 경우 한글자씩 다시 저장하는 것이고
아래는 한글이고 공백이 아닌 경우 decompose 해서 자음,모음,종성으로 구분해서 담는 것이다.
첫번째 결과와 두번째 결과는 다음과 같다.